
Contents
The Philosophy
Imagine a world where buildings don’t touch the ground and the slides at the kid’s playground are completely horizontal. There’s an app to order rain and people are 4 times as small. That world is the hallucination-fueled world of generative AI. You can imagine these things but they could never actually exist.
After one week of lying to myself about the how bad unfiltered AI answers were, I decided to give in and make my first two major pivots.
Pivot 1
AI clearly couldn’t be trusted to give valuable answers to user questions so the first pivot was to creating an AI-assisted problem solver instead of a Q&A platform. The idea was to converse with various AI chat bots to navigate towards a real solution.
I had several meandering thoughts on where to take this and how to pitch it. Perhaps it could have been a way to share context between LLMs (ex. pass your Gemini chat to Claude) or an interface for chatting with multiple agents at once. It wasn’t a terrible idea but it was hard to summarize in a simple way and you could argue that chatting with a single high-powered model like Claude Opus or GPT-4 would be equally effective. Plus, it was still entirely dependent on AI. If the AI models didn’t know the real answer, you weren’t going to “navigate” there.
Pivot 2
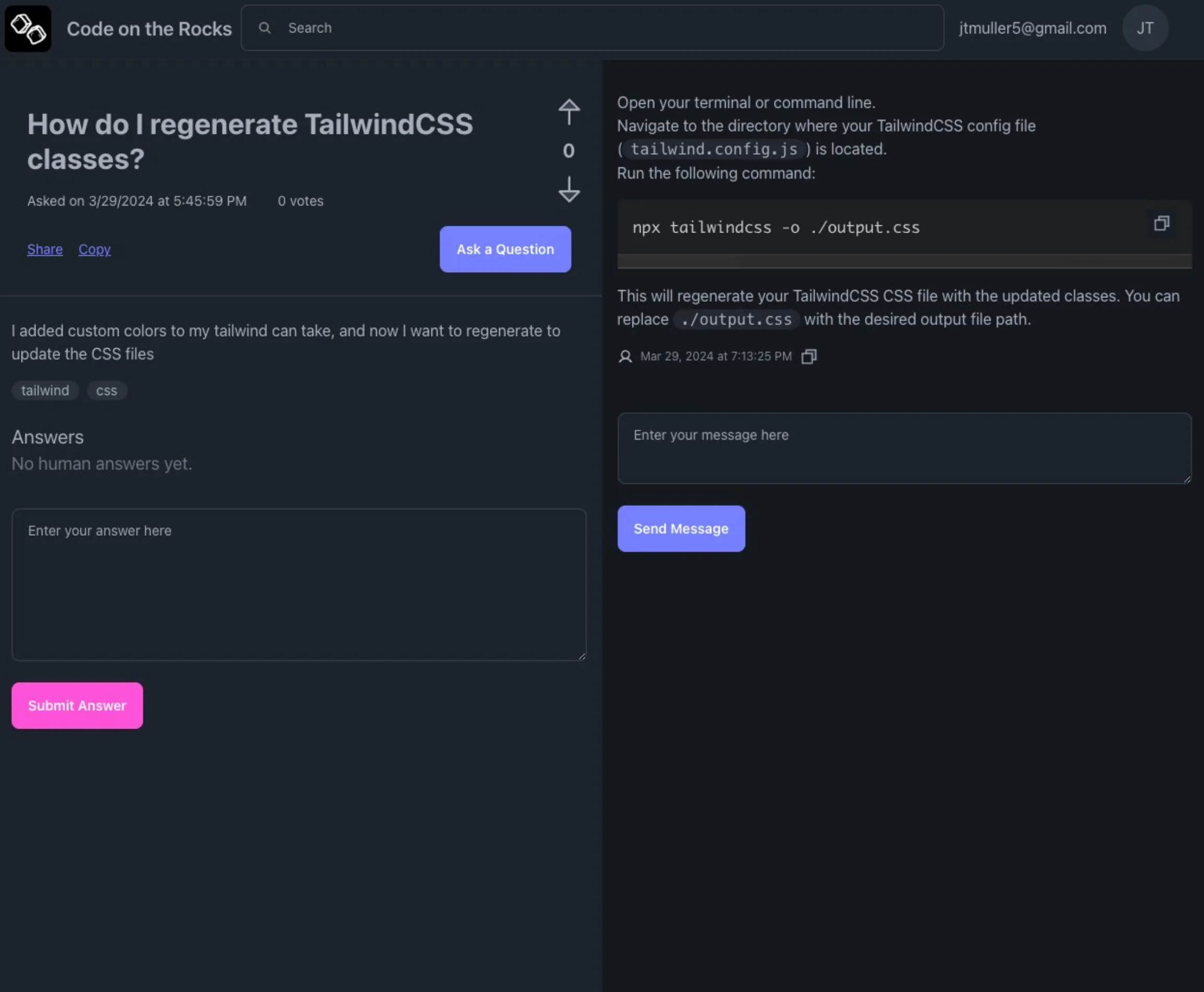
Another night of sleep led me to pivot again, this time towards something that resembeled the MVP. This version of COTR is a platform designed to accelerate the creation of concise developer tutorials with the help of AI. The sequence of events looks like this:
- 🤔 Users create Tasks
- 🥩 Generative AI models create step-by-step guides to complete those tasks
- 👨🍳 Humans edit and refine the guides
- 🍲 Everyone benefits
I’ve replaced “questions” and “answers” from the Stack Overflow universe with “tasks”, imperatively phrased commands aimed at completing something specific. For example:
- Create a React app with TypeScript and TailwindCSS
- Create a Custom React Hook to Fetch Data from an API
- Send a Slack Notification when Data is Added to Supabase
Each task will be accompanied by a guide outlining the set of steps to complete it. The first version of each guide will be generated by AI and is expected to be inaccurate in one way or another. The idea is to have human reviewers remove hallucinations, add links, and generally make sure the guide does what it claims to do.
This pivot places a significant value on the concept of a human “edit”. A guide that has been edited multiple times is assumed to be more reliable than a guide that is unedited.



The Software
Pivoting twice comes with a cost. I spent most of my development time this week refactoring the website away from the Q&A infrastructure towards a task-first one. Now users will submit a task title and a step-by-step guide will be created using Gemini Pro.
The Prompt:
Create a step by step guide to:
{DO THE THING}
Each new step should start with a "#" Heading
Be concise and use Markdown
Because editing is now crucial to the success of the platform, I also introduced an editing feature that lets anyone update any guide. Each version is saved to a task_history table in Supabase with the ID of the last user who touched it. This might be extremely unneccessary, especially given the scale of the website at the moment but I can see a future where bad edits need to be rolled back. In researching this problem, I discovered that the entire edit history of Wikipedia takes up 10TB of space. I can’t afford that.
The Numbers
I used the DaisyUI Stat component to add the primary stats to the COTR home page:

- Days Since Launch: 14
- Total Tasks: 47
- Total Sign Ups: 7
- Total Users: 166
Overall this was a slow (by that I mean immobile) week for user sign ups but that’s fine. The goal for next week is to focus more on the total number of Tasks and edits submitted to the system.
The Business
SEO
A big focus this week has been on improving the website’s discoverability. I learned about Google’s Search Console and more specifically the URL inspection tool that can be used to determine if a page is indexed with Google.
I also read an old post from the founder of Stack Overflow on the importance of a sitemap. While it won’t solve all of your indexing problems, the author explains that it can really help Google crawlers figure out what there is to discover.
Stack Overflow’s own sitemap.xml page is inaccessible since it was apparently being abused but from what I’ve read, it basically contains direct links to every question on SO. In an attempt to copy that approach, I created a little script to read every task in my Supabase database and write it to a sitemap file:
const { createClient } = require("@supabase/supabase-js");
require("dotenv").config();
const fs = require("fs");
// Initialize the Supabase client
const supabaseUrl = process.env.REACT_APP_SUPABASE_URL;
const supabaseKey = process.env.REACT_APP_SUPABASE_ANON_KEY;
const supabase = createClient(supabaseUrl, supabaseKey);
// Function to generate the sitemap XML
function generateSitemap(tasks) {
const baseUrl = "https://codeontherocks.dev";
const today = new Date().toISOString().slice(0, 10);
let sitemap = `<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">`;
tasks.forEach((task) => {
const { id, title } = task;
const slug = title.toLowerCase().replace(/[^a-z0-9]+/g, "-");
const url = `${baseUrl}/task/${id}/${slug}`;
sitemap += `
<url>
<loc>${url}</loc>
<lastmod>${today}</lastmod>
<changefreq>daily</changefreq>
<priority>1.0</priority>
</url>`;
});
sitemap += `
</urlset>`;
return sitemap;
}
// Function to fetch tasks from Supabase and generate the sitemap
async function generateTaskSitemap() {
try {
const { data: tasks, error } = await supabase
.from("tasks")
.select("id, title");
if (error) {
throw new Error("Failed to fetch tasks from Supabase");
}
const sitemap = generateSitemap(tasks);
// Write the sitemap to a file
fs.writeFile("./public/sitemap.xml", sitemap, (err) => {
if (err) {
console.error("Error writing sitemap to file:", err);
} else {
console.log("Sitemap saved to sitemap.xml");
}
});
} catch (error) {
console.error("Error generating sitemap:", error);
}
}
// Run the script
generateTaskSitemap();
Google is indexing it as I type this.
Competitors
I did a little digging this week and found a handful of competitors, both large and small.
If anything, doing this deep dive made me a little depressed. All of these alternatives aside from SO are sad and lonely places that no one knows about.
Things that don’t scale
Paul Graham wrote a now famous essay in 2013 about doing things that don’t scale in order to help your startup take off. There are all kinds of stories of founders doing ridiculous things in their company’s early days to fan the flames of growth:
- AirBnB founders taking pictures at new apartments
- Pinterest CEO pulling up Pinterest website on all computers at the Apple store
- Groupon manually adding coupons
- DoorDash founders delivering food
Early in the week I started doing my own thing that didn’t scale (or end well). I used Stack Overflow’s advanced search features to find recently closed issues with a negative score or very little views and then posted a link to the same question on the COTR platform:
[typescript] closed:yes score:-2
[javascript] views:0..10 closed:yes
This was before either of this week’s pivots so I was basically throwing these users at an AI model and saying “Check it out!“.
I was banned from Stack Overflow. Temporarily, at least. I like SO too much to risk being kicked out permanently so I’ll be thinking about a new marketing strategy.